[01] Za pomoci nástroje file získáme základní informace o analyzovaném souboru
# file netc
netc: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), for GNU/Linux 2.2.5, statically linked, stripped
Jak je vidět, analyzovaný soubor byl zkompilovaný staticky a prošel procesem strippingu.
[02] Hledáme v souboru zajímavé řetězce znaků
# strings -a netc > strings.out
Při analýze obsahu souboru najdeme následující informace, které nám budou potřebné při další práci:
|
Jiný způsob pro nalezení zajímavých řetězců znaků může být prohledání obsahu vybraných sekcí analyzovaného souboru. Například informace o systému a verzi kompilátoru, která
byla požita pro kompilaci souboru, se standardně zapisuje do sekce .comment. Obsah této sekce souboru můžeme přečíst pomocí příkazu: # objdump -j .comment -s název_programu > comment.out lub # objdump -h název_programu > sections.out a náhled libovolným editorem nebo prohlížečem obsahu souborů, umožňující skok na daný offset. |
[03] Vyhledáme a stáhneme z Internetu knihovny, které mohly být použité během kompilace
Z výsledku příkazu strings v kroku [02] víme, že soubor byl zkompilovaný v systému Mandrake Linux 10.0
s použitím kompilátoru GCC 3.3.2. V našem případě se omezíme pouze na vytvoření symbolů souvisejících s knihovnou
libc, pocházející ze systému Mandrake 10.0. S ohledem na určení knihovny libc
můžeme ji s velkou pravděpodobností určit za použitou v analyzovaném souboru. Jiná knihovna, která také
může být standardně využita v procesu vytváření tabulky symbolů, je knihovna libgcc.a.
My se ale budeme zabývat výlučně knihovnou libc, protože elementy knihovny libgcc.a rozpoznáme v další části, porovnáním s příkladovým zkompilovaným programem.
Knihovnu libc.a uložíme do adresáře ~/analysis/libc_components/
| Co dělat, když nemáme informace, které by nám mohly pomoci při zjištění verze knihoven využitých během kompilace? V této situaci můžeme použít několik různých verzí knihoven i pro několik různých distribucí systému, provést níže uvedené kroky procesu vytváření tabulky symbolů a zhodnotit získané výsledky . |
[04] Rozpakujeme objekty knihovny
# ar x libc.a
[05] Kontrolujeme, zda analyzovaný program obsahuje kód jednotlivých objektu
knihovny
# search_static netc ~/analysis/libc_components > obj_file
V tomto kroku je třeba si všimnout kolizí, které by se mohly objevit během prováděné kontroly.
Nalezené kolize se nacházejí v koncové části souboru obj_file. Jaký praktický význam a jaký vliv mají kolize na analýzu? Bez analýzy kódů jednotlivých funkcí, pro které kolize nastaly, se nedá jednoznačně říct, která z funkcí ve skutečnosti byla v programu využita.
Příklad odhalené kolize:
# Possible conflict below requiring manual resolution:
# ----------------------------------------------------
# /analysis/libc_components/getsrvbynm.o - match at 0x08057580 (0x000000ea bytes)
# /analysis/libc_components/getsrvbypt.o - match at 0x08057580 (0x000000ea bytes)
[06] Generujeme seznam nalezených symbolických odkazů z jednotlivých objektů knihovny
# gensymbols obj_file > symbols_db
Výsledkem činnosti skriptu je seznam symbolů současně s adresami, na kterých můžeme najít jejich kód.
[07] Disasemblujeme analyzovaný program
# gendump netc > out1
[08] Odstraníme kód nalezených funkcí knihovny ze souboru out1
# decomp_strip obj_file < out1 > out2
[09] Abychom si analýzu usnadnili, přidáváme názvy hledaných funkcí k místum,
ze kterých byly vyvolány.
# decomp_insert_symbols symbols_db < out2 > out3
[10] Pro zvětšení čitelnosti kódu v místech odkazů na řetězce znaků vložíme jejich obsah
# decomp_xref_data netc < out3 > out4
|
Pro vytvoření obsahu tabulky symbolů můžeme také využít nástroje z balíčkufenris.
Další kroky: [a] Otevřeme skript pro editaci getfprints [b] Do parametru TRYLIBS zapíšeme cesty nebo jména knihoven, ze kterých chceme vytvořit databázi signatur # getfprints [c] Změníme jméno výsledného souboru na libovolné jméno souboru signatur # mv NEW-fnprints.dat fnprints.dat [d] Použijeme program dress k vytvoření odstraněných symbolů # dress -F ./fnprints.dat jmeno_programu > seznam_vytvořených symbolů nebo # dress -F ./fnprints.dat jmeno_programu jmeno_programu_s_pridanym_seznamem_symbolu |
Pokud je známa verze kompilátoru použitého pro kompilaci analyzovaného programu (a my ji známe) nebo
si tuto informaci můžeme domyslet, můžeme udělat zkoušku zjištění lokalizace funkcí dodaných kompilátorem
(podobný efekt by chom měli získat využitím knihovny libgcc.a v procesu vytváření tabukly symbolů).
Pro provedení této činnosti využijeme porovnání příkladového programu zkompilovaného stejným kompilátorem jako analyzovaný soubor.
[11] Vytváříme ukázkový program sample.c
int main(int argc, char **argv[])
{
return 0;
}
[12] Kompilujeme příkladový program
# gcc -static -o sample sample.c
[13] Porovnáváme elementy zkompilovaného programu s kódem analyzovaného souboru – out4
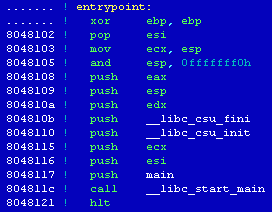
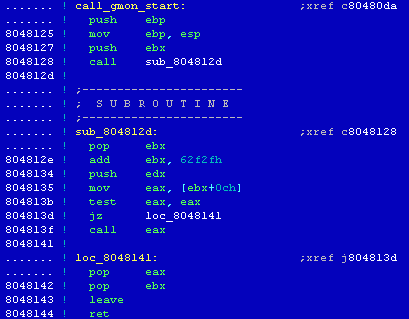
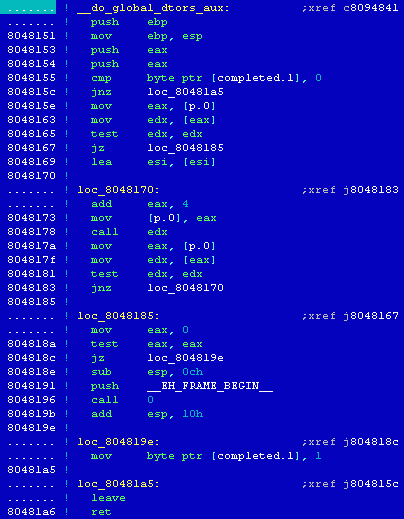
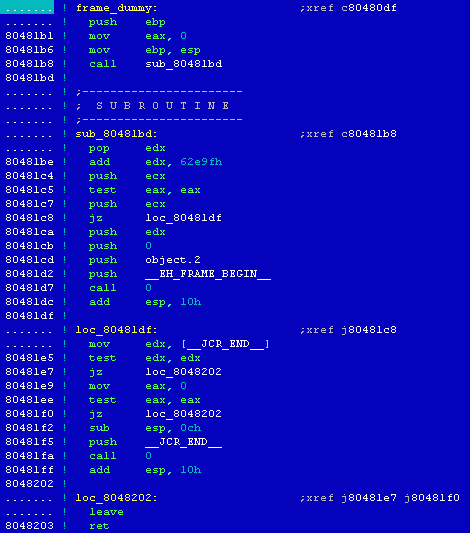
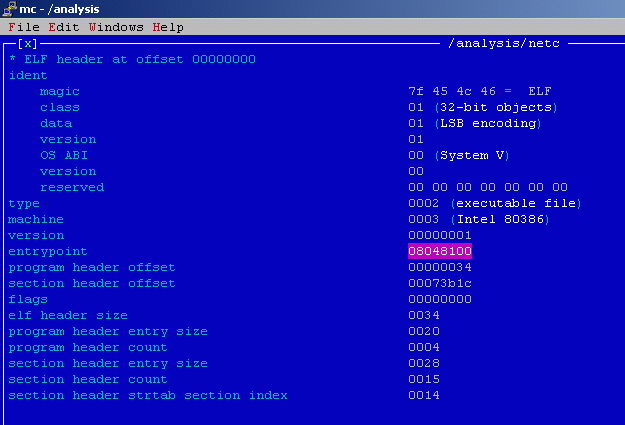
[14] Porovnáním struktury funkce _start() z příkladového programu sample s kódem této funkce
nalezené v analyzovaném souboru nalézáme lokaci funkce main()
08048100: xor %ebp,%ebp
08048102: pop %esi
08048103: mov %esp,%ecx
08048105: and $0xfffffff0,%esp
08048108: push %eax
08048109: push %esp
0804810a: push %edx
0804810b: push $0x804aa90
08048110: push $0x804aa30
08048115: push %ecx
08048116: push %esi
08048117: push $0x804994f
0804811c: call 0x0804a3b0 <__libc_start_main>
08048121: hlt
[15] Zjišťujeme funkce uživatele (pro přesnost -- funkce, které nebyly rozpoznány jako objekty knihovny)
# grep 'call 0x' out4 | grep -v '<' > user_f.out
[16] Protože se v analyzovaném kódu mnoho volaných funkcí opakuje, pokusíme se získat pouze unikátní adresy funkcí
# grep 'call 0x' out4 | grep -v '<' | awk '{print $3}' | sort -u
0x0804812d
0x080481bd
0x08048204
0x080482a5
0x08048303
0x0804834b
0x080483b5
0x080483fd
0x080486b8
0x080488ab
0x08048951
0x080489b3
0x08048a3b
0x08048d9d
0x08049235
0x08049311
0x0804950b
0x0804aed0
0x0804bf70
0x0804bf90
0x08057370
0x08057580
Jak je vidět, část získaných adres v našem kódu být nemusíout4.
Jejich nepřítomnost vyplývá z existence kolizí signatůr funkcí, které v kroku [8] byly odstraněny.
[17] V dalších krocích, začínajíc od funkce main() musíme provést analýzu předávání kontroly mezi funkcemi uživatele a jimi realizovaných činností. V tomto kroku
musíme získat odpovědi na otázky typu: jakou úlohu plnil analyzovaný objekt v systému a jaké
mechanizmy využívá. Pro samotnou interpretaci činností realizovaných jednotlivými funkcemi
se vyžaduje znalost jazyka Assembler, minimálně na základní úrovni.
Funkce main()
0x0804812d
0x080481bd
0x08048204
0x080482a5
0x08048303
0x0804834b
0x080483b5
0x080483fd
0x080486b8
0x080488ab
0x08048951
0x080489b3
0x08048a3b
0x08048d9d
0x08049235
0x08049311
0x0804950b