[01] Za pomocą narzędzia file uzyskujemy podstawowe informacje o analizowanym pliku
# file netc
netc: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), for GNU/Linux 2.2.5, statically linked, stripped
Jak widać, analizowany plik został skompilowany statycznie i przeszedł proces strippingu.
[02] Wyszukujemy w pliku interesujące łańcuchy znaków
# strings -a netc > strings.out
Analizując otrzymaną zawartość pliku odnajdziemy następujące informacje, które będą pomocne w dalszych działaniach:
|
Innym sposobem na odszukanie interesujących łańcuchów znaków może być przeszukanie zawartości
wybranych sekcji analizowanego pliku. Na przykład informacje o systemie i wersji kompilatora, która
została użyta do kompilacji pliku, standardowo przechowywane są w sekcji .comment. Zawartość wskazanej sekcji pliku możemy odczytać stosując polecenie: # objdump -j .comment -s nazwa_programu > comment.out lub # objdump -h nazwa_programu > sections.out i podejrzenie dowolnym edytorem lub przeglądarką zawartości pliku pod wskazanym offsetem. |
[03] Wyszukujemy i pobieramy z Internetu biblioteki, które mogły być użyte w trakcie kompilacji
Z wyniku działania polecenia strings w kroku [02] wiemy, że plik został skompilowany w systemie Mandrake Linux 10.0
przy zastosowaniu kompilatora GCC 3.3.2. W naszym przypadku ograniczymy się do próby odtworzenia
symboli związanych z biblioteką libc, pochodzącą z systemu Mandrake 10.0. Ze względu na przeznaczenie biblioteki libc
można z dużym prawdopodobieństwem założyć jej wykorzystanie w analizowanym pliku. Inną biblioteką, którą również
można byłoby standardowo wykorzystać w procesie odtwarzania tablicy symboli, jest biblioteka libgcc.a.
My jednak ograniczymy się wyłącznie do biblioteki libc, ponieważ elementy biblioteki libgcc.a rozpoznamy w dalszej
części, poprzez porównanie z przykładowo skompilowanym programem.
Bibliotekę libc.a zapisujemy w katalogu ~/analysis/libc_components/
| Co zrobić, jeśli nie posiadamy informacji, które mogłyby nam pomóc w ustaleniu wersji bibliotek zastosowanych w trakcie kompilacji? W tej sytuacji można pobrać kilka różnych wersji bibliotek nawet dla kilku różnych dystrybucji systemu, wykonać poniższe kroki procesu odtwarzania tablicy symboli oraz ocenić otrzymane wyniki pod względem skuteczności i ilości trafień. |
[04] Rozpakowujemy obiekty biblioteki
# ar x libc.a
[05] Sprawdzamy, czy w analizowanym programie zawarty jest kod poszczególnych obiektów biblioteki
# search_static netc ~/analysis/libc_components > obj_file
W tym kroku należy również zwrócić uwagę na kolizje, które mogły się pojawić w trakcie dokonanej weryfikacji.
Wykryte kolizje znajdują się w końcowej części pliku obj_file. Jakie znaczenie
praktyczne i jaki wpływ na analizę mają kolizje? Takie, że bez szczegółowej analizy kodu funkcji, dla których
wystąpiły kolizje nie daje się jednoznacznie określić, która z funkcji w rzeczywistości została w programie
zastosowana.
Przykład wykrytej kolizji:
# Possible conflict below requiring manual resolution:
# ----------------------------------------------------
# /analysis/libc_components/getsrvbynm.o - match at 0x08057580 (0x000000ea bytes)
# /analysis/libc_components/getsrvbypt.o - match at 0x08057580 (0x000000ea bytes)
[06] Generujemy listę odnalezionych odniesień symbolicznych z poszczególnych obiektów biblioteki
# gensymbols obj_file > symbols_db
Wynikiem działania skryptu jest lista symboli wraz z adresami, pod którymi można znaleźć ich kod.
[07] Przeprowadzamy dessassemblację analizowanego programu
# gendump netc > out1
[08] Usuwamy kod odnalezionych funkcji biblioteki z pliku out1
# decomp_strip obj_file < out1 > out2
[09] Dla ułatwienia analizy dodajemy nazwy odnalezionych funkcji w miejsca ich wywołań
# decomp_insert_symbols symbols_db < out2 > out3
[10] Dla zwiększenia czytelności kodu w miejsca odniesień do łańcuchów znaków wstawimy ich treść
# decomp_xref_data netc < out3 > out4
|
Do odtworzenia zawartości tablicy symboli można również zastosować narzędzia z pakietu fenris.
Kolejne kroki: [a] Otwieramy do edycji skrypt getfprints [a] W parametrze TRYLIBS wpisujemy ścieżki oraz nazwy bibliotek, z których chcemy utworzyć bazę sygnatur # getfprints [b] Zmieniamy nazwę pliku wynikowego na domyślną nazwę pliku sygnatur # mv NEW-fnprints.dat fnprints.dat [c] Wykorzystując program dress odtwarzamy usunięte symbole # dress -F ./fnprints.dat nazwa_programu > lista_odtworzonych symboli lub # dress -F ./fnprints.dat nazwa_programu nazwa_programu_z_dodana_lista_symboli |
Jeżeli znana jest wersja kompilatora zastosowanego do kompilacji analizowanego programu (a my ją znamy) lub
możemy się domyślać tej informacji, można podjąć próbę określenia lokalizacji funkcji dodanych przez kompilator
(podobny efekt powinniśmy uzyskać wykorzystując bibliotekę libgcc.a w procesie odtwarzania tablicy symboli).
Do przeprowadzenia tego działania wykorzystamy porównanie przykładowego programu skompilowanego tym samym
kompilatorem co analizowany plik.
[11] Tworzymy przykładowy program sample.c
int main(int argc, char **argv[])
{
return 0;
}
[12] Kompilujemy przykładowy program
# gcc —static —o sample sample.c
[13] Porównujemy elementy skompilowanego programu z kodem analizowanego pliku - out4
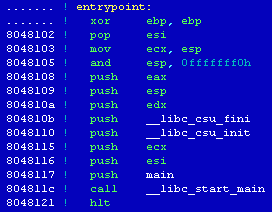
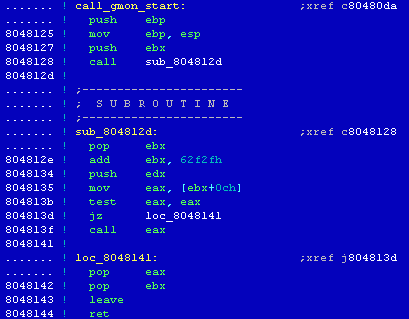
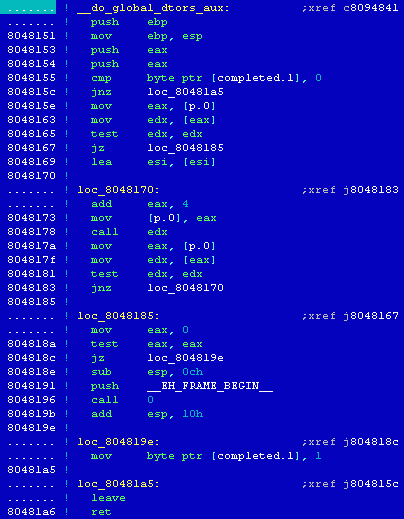
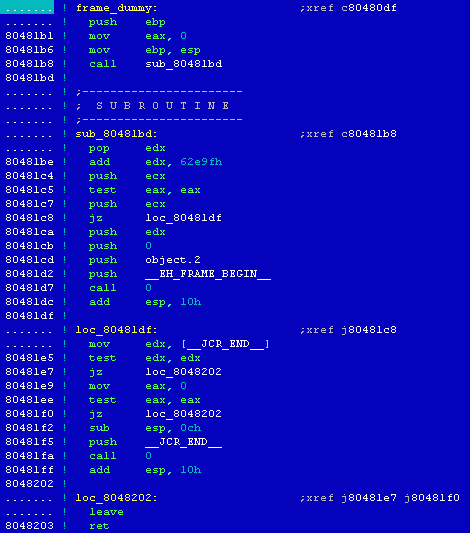
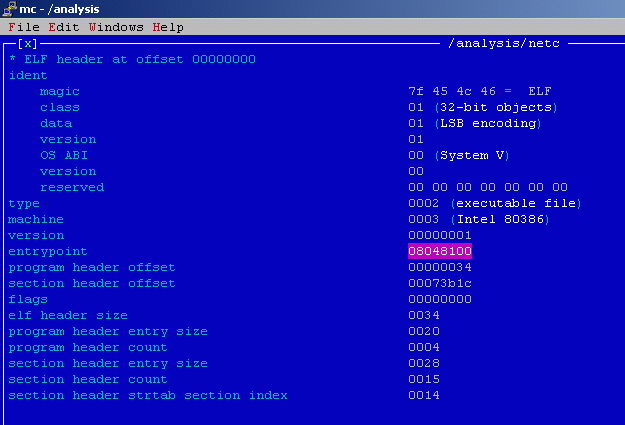
[14] Porównując budowę funkcji _start() z przykładowego programu sample z kodem tej funkcji
odnalezionej w analizowanym pliku ustalamy lokalizację funkcji main().
08048100: xor %ebp,%ebp
08048102: pop %esi
08048103: mov %esp,%ecx
08048105: and $0xfffffff0,%esp
08048108: push %eax
08048109: push %esp
0804810a: push %edx
0804810b: push $0x804aa90
08048110: push $0x804aa30
08048115: push %ecx
08048116: push %esi
08048117: push $0x804994f
0804811c: call 0x0804a3b0 <__libc_start_main>
08048121: hlt
[15] Ustalamy funkcje użytkownika (dla ścisłości - funkcje, które nie zostały rozpoznane jako obiekty biblioteki)
# grep 'call 0x' out4 | grep -v '<' > user_f.out
[16] Ponieważ w analizowanym kodzie wiele wywoływanych funkcji się powtarza, spróbujemy uzyskać wyłącznie
unikalne adresy funkcji
# grep 'call 0x' out4 | grep -v '<' | awk '{print $3}' | sort -u
0x0804812d
0x080481bd
0x08048204
0x080482a5
0x08048303
0x0804834b
0x080483b5
0x080483fd
0x080486b8
0x080488ab
0x08048951
0x080489b3
0x08048a3b
0x08048d9d
0x08049235
0x08049311
0x0804950b
0x0804aed0
0x0804bf70
0x0804bf90
0x08057370
0x08057580
Jak się okazuje, część z uzyskanych adresów może nie istnieć w naszym kodzie out4.
Ich brak wynika z istnienia kolizji sygnatur funkcji, które w kroku [8] zostały usunięte.
[17] W kolejnych krokach, zaczynając od funkcji main() powinniśmy dokonać analizy przepływu
kontroli pomiędzy funkcjami użytkownika oraz realizowanych przez nich działań. Przechodząc ten krok
powinniśmy uzyskać odpowiedź na pytania typu: jaką rolę pełnił analizowany obiekt w systemie oraz jakie
mechanizmy wykorzystuje. Do właściwej interpretacji działań realizowanych przez poszczególne funkcje
wymagana jest znajomość języka Assembler prznajmniej w stopniu podstawowym.
Funkcja main()
0x0804812d
0x080481bd
0x08048204
0x080482a5
0x08048303
0x0804834b
0x080483b5
0x080483fd
0x080486b8
0x080488ab
0x08048951
0x080489b3
0x08048a3b
0x08048d9d
0x08049235
0x08049311
0x0804950b